FreiData: InvenioRDM at the University of Freiburg

Image by Sandra Meyndt/University of Freiburg
When InvenioRDM launched on 27th of October 2023 at the University of Freiburg under the label FreiData, campus storage options which minted DOIs for publications already existed. For over a decade, Freiburg has hosted an institutional repository called "FreiDok“, which is also used as a documentation system for the university's publication activity. In its policies for handling research data and for Open Science, the university recommends that researchers prioritize visibility to their key target audience as the most important criterion when publishing research data. This often leads researchers to choose externally operated repositories.
Why did the University of Freiburg still decide to establish its own instance of InvenioRDM? And why did the university's management commit to sustainable operation?
Motivated by the principles of scientific accountability enshrined in the state higher education law of Baden-Württemberg, as well as globally increasing scholarly adoption of Open Science best practices, University of Freiburg has embraced the publication of research results (i.e., data) as a fundamental mission of the university. In its Open Science policy, the university has set the goal of independent operation at the infrastructure level, acknowledging that local repository control allows more flexibility for researchers. While the established FreiDok service could accommodate research data, on a technical level, it could only handle smaller data volumes. These limits were established at a time when larger volumes of research data were not typically intended for publication. Therefore, there was a need for an addition to the existing service to connect storage systems with greater capacity in the background. During the same period, an object storage system with several petabytes of capacity was put into operation. This storage is operated in the same server room from which the local instance of InvenioRDM is delivered.
Automation and FAIRness are crucial desired features for storage of Freiburg's large-volume research datasets. Both local research data and larger Open Science policies require Findability and Accessibility of datasets, Interoperability, and clear guidelines for data Reusability. For all these features to be delivered as concisely and easily as possible is key. InvenioRDM meets the challenge in various ways, including automatically issuing DOIs for deposits, use of the DataCite metadata schema, use of open protocols, clear licensing options, and having a corresponding REST API for every function available on the web interface. These are vital tools for allowing researchers and institutions to map the lifecycle of research data. However, launching the repository is just the first step. The next step is to engage researchers to use InvenioRDM.
FreiData and User Engagement
Data quality control and user control of datasets were clear local use cases and needs for the InvenioRDM instance. An InvenioRDM feature which accommodates both needs is the ability to create communities in a self-service manner, where registered users can come together. Community owners can personalize their space and assign their communities distinct names via a brief abbreviation. The abbreviation is appended to the domain name of the InvenioRDM instance and serves as the hostname for the group's deposited research outputs.
In a community, various roles with increasing permission levels are predefined: Reader, Curator, Manager, and Owner. In addition to controlling community branding and membership, those with higher permissions can initiate more focused tasks, such as assigning review of a resource to another community member before its record is published and issued a DOI. The nuanced roles allow the establishment of group-specific workflows through which internal review and quality control can be achieved for all deposits. Such review processes allow each community to set quality standards for its FreiData publications. The criteria for these quality standards can be defined and documented by the community itself.
In this way, communities organized around specific subjects leverage their own expertise to ensure high-quality data deposits. The resultant benefits to individual researchers, to the communities that they form, and to both data depositors and data re-users, are the underpinnings of growing user engagement with FreiData. And if this engagement continues to increase, it bodes well for the long-term sustainability of FreiData.
Despite desire for local repository control, University of Freiburg never intended to tax its capacities to the point of offering all repository IT services in-house. From the beginning, the operational planning of "FreiData" included the intention to make its InvenioRDM installation available to others. The DataPLANT consortium, a partner within the National Research Data Infrastructure (NFDI), operates another instance of this InvenioRDM installation under its own domain. Partners in this installation offer each other mutual support, leading to sustainable operation.
The computing center of the University of Freiburg supports work on its installation through its involvement in the InvenioRDM Developer Community.
Zenodo/InvenioRDM participation at GREI Annual Meeting, Chicago

Merchandise Mart, River North, Chicago, IL by w_lemay, CC BY-SA 2.0 via Wikimedia Commons
{kind=link}
On September 19-20, 2024, members from the seven participating repositories in the Generalist Repository Ecosystem Initiative (GREI) met in Chicago for the GREI Year 3 Annual Meeting to celebrate the achievements of Year 3 of the National Institutes of Health (NIH)-funded, data sharing and open science-focused, four-year initiative. The event was held at Chicago’s historic Merchandise Mart at MATTER, a global healthcare startup incubator, community nexus, and corporate innovation accelerator.
The GREI program’s primary mission is to establish a common set of cohesive and consistent capabilities, services, metrics, and social infrastructure across generalist repositories. The program’s secondary mission is to raise general awareness and help researchers adopt FAIR principles to better share and reuse data. This is particularly important for the health research community to fulfill data sharing requirements per the NIH’s Policy on Data Management and Sharing. Generalist repositories are essential infrastructure to enable data sharing when discipline-specific or institutional repositories cannot be identified or do not exist.
The plans for the third year of GREI have been nearly fully implemented, and the group that gathered in Chicago last month reported on outcomes and completed planning exercises for priorities for Year 4. The Year 3 plan is published and available on GitHub, and is broken down into eight objectives. Below is an outline of how Zenodo representatives contributed to each objective, foundational work which often aligned with improvements being made for the InvenioRDM development and user communities:
Desirable Characteristics for All Data Repositories (for sharing scientific data)
- Zenodo team members co-led the effort to update the Generalist Repository Comparison Chart, a tool to help researchers select the best generalist repository to meet their needs. The new version is projected for Spring 2025
- Zenodo team members co-led the team which created the Generalist Repository Selection Flowchart, a tool designed to guide users through a series of considerations while selecting the best repository to share data
Consistent Metadata
- Zenodo and InvenioRDM continue to adhere to the recommended GREI standard, which incorporates the DataCite metadata schema. In addition, InvenioRDM already has capability for further suggested metadata enhancements, such as incorporation of LCSH and MeSH subject headings and CRediT contributor role taxonomy roles
Search & Browse
- Work is ongoing to explore a cross-GREI-repository search option. Meanwhile, InvenioRDM has already achieved a further recommendation: incorporation of ROR, the identification registry for research organizations
Analytics & Reporting
- Zenodo team members are co-leading the effort to share the Make Data Count usage metrics with the wider community via DataCite
Use Cases
- Zenodo team members co-led the task group responsible for updating the Use Case catalog with two new use cases: one outlining a scenario where a researcher utilizes a generalist repository in lieu of a local institutional repository, and one scenario where a researcher must deposit portions of a heterogenous dataset into several different repositories, one of which is a generalist repository
Connecting Digital Objects
- Zenodo team members are working on the effort to map DataCite relationTypes to all types of non-data research objects, and to submit any needed updates to DataCite via API
- InvenioRDM has also completed work on the FAIR signposting recommendation, thanks to Guillaume Viger’s work on signposting
QA/QC
- Zenodo team members are contributing to a comprehensive review and report on approaches to handling personal or sensitive data, as well as a comprehensive review of how QA/QC on data is done at each GREI repository
Training & Community Engagement
- Zenodo team members are actively involved in the multiple GREI webinars, conference proposals, and blog posts produced each project year
The GREI-Zenodo team members look forward to continuing our efforts through all the above projects, and new ones in Year 4, to provide an interoperable, robust repository option to US-based health researchers. Additional GREI milestones that can positively impact InvenioRDM development will be reported on in future telecons.
This work was supported by the National Institutes of Health (NIH) Office of Data Science Strategy/Office of the NIH Director pursuant to OTA-21-009, “Generalist Repository Ecosystem Initiative (GREI)” through Other Transactions Agreement (OTA) Number OT2DB000013.
InvenioRDM v12.0 released
We are happy to announce the release of InvenioRDM v12.0! Released on August 1, 2024, it is the first InvenioRDM release since v11.0 was released on January 23, 2023, and it includes not only many bug fixes and small improvements but also several major new features listed below.
Since the v11.0 release several InvenioRDM partners have launched InvenioRDM instances in production, including Zenodo, which migrated to InvenioRDM in October 2023. A number of these partners have migrated already to InvenioRDM v12.0 or plan to do so in the coming months.
German translations for v12 will be coming in v12.1 targeted for release in October 2024. We hope that other language translations will follow suit. Work on InvenioRDM v13.0 has already started and you can track it here.
Try it
Want to try the new features in v12.0? Just head over to the demo site: https://inveniordm.web.cern.ch. If you want to install it, follow the installation instructions at https://inveniordm.docs.cern.ch/install/.
Release Notes
See the full release notes at https://inveniordm.docs.cern.ch/releases/v12/version-v12.0.0/ and the upgrade guide at https://inveniordm.docs.cern.ch/releases/v12/upgrade-v12.0/.
What’s new?
Usage statistics compliant with MakeDataCount and COUNTER
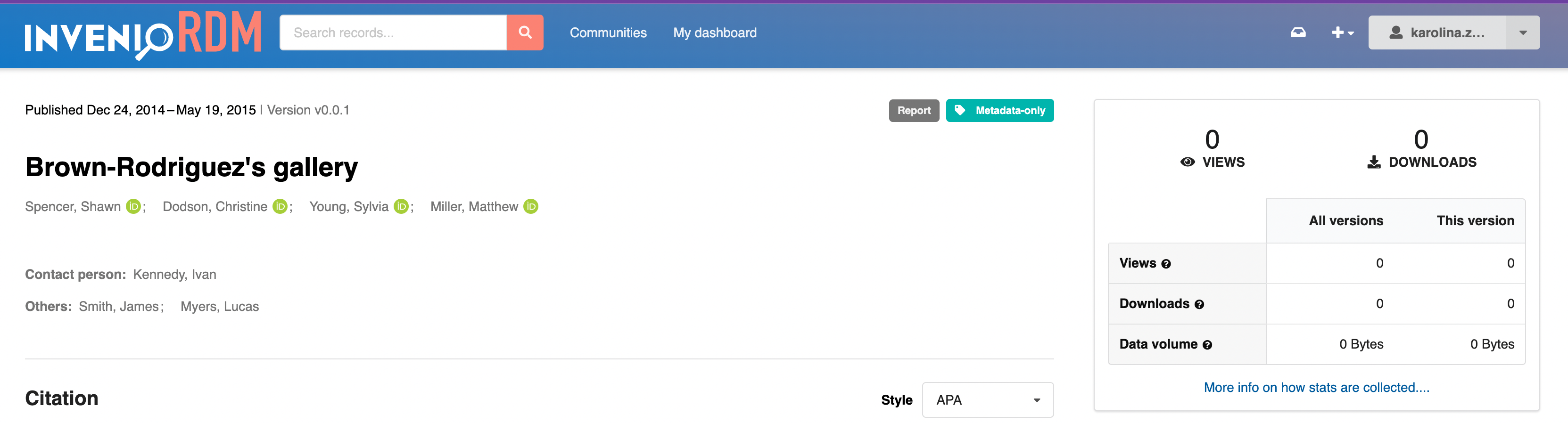
A major new feature in this release is the integration of invenio-stats, a powerful and flexible extension for measuring usage statistics of InvenioRDM records. Usage statistics are compliant with the MakeDataCount and COUNTER standards. Usage statistics are displayed in the record landing page and record search:
Record inclusion in multiple communities
A record can now belong to multiple communities. Including a record in multiple communities will let different curators change the files or metadata of the record.
Powerful and reliable record access
Giving and requesting access to records have seen a complete overhaul in this release. Record owners or curators can share them directly with other users or with groups, as well as control whether, with whom, and how access can be demanded.
Notifications
A notification system has been introduced. Users can now receive email notifications depending on their preferences when they are involved in certain activities.
Moderation of users and records
The administration panel now includes a "User Management" section to suspend, block and delete users, and undo all those actions. Records can also be deleted (with a grace period for appeal or undoing), which empowers administrators to enforce institutional policies and fight spam.
DOIs for concept records and no DOIs for restricted records
InvenioRDM now mints a concept DOI for every record by default, similar to what Zenodo has done for many years. Along with this update, restricted records will now stop minting a DOI upon publication thus keeping private records truly private.
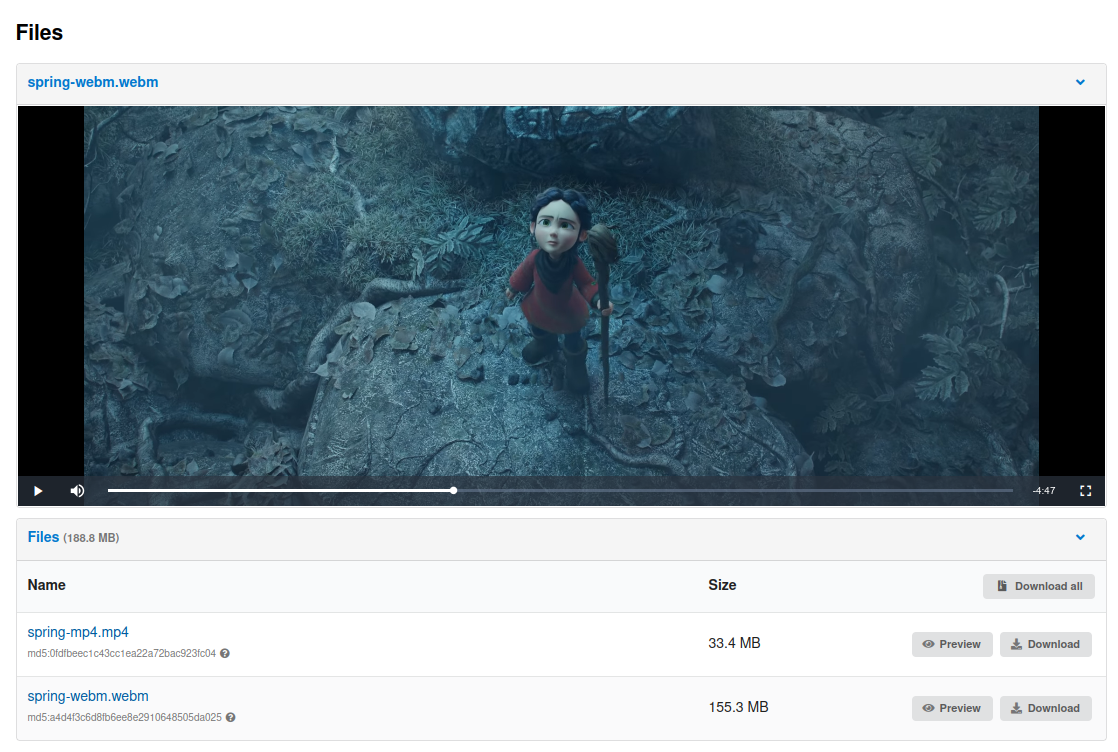
Even better previewers
Audio and video previewers come by default. Tiling support for the International Image Interoperability Framework (IIIF) API standards is available. Text previewing has been made much more resilient.
External resources integration (e.g. GitHub)
The landing page for a record can now provide nicer visuals for configured related works. A configuration variable can be set to highlight some of the referred platforms.
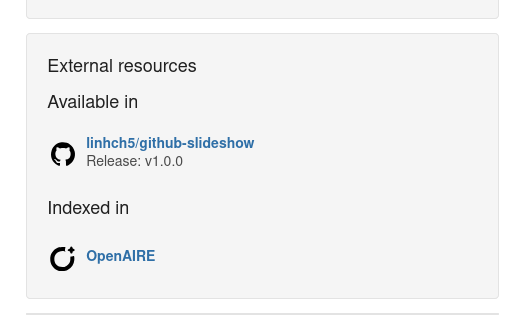
Skippable community submission review
With InvenioRDM v12, you can adjust whether a record review is always required for your community, or if curators, managers, and owners can submit a record without the review process.
Banners
With the addition of invenio-banners, you can easily add and manage important alerts and messages on your InvenioRDM instance, such as system maintenance notifications or announcements.
Static pages - administration panel
Another notable addition is the integration of invenio-pages with the administration panel. It exposes a convenient UI to create and manage static pages.
Breaking changes
Make sure to read the Breaking Changes section in the release notes.
Limitations and known issues
- Translations for v12 will be coming in v12.1 targeted for release in October 2024.
- Sharing a secret link to a restricted record in a restricted community does not provide access to the record yet. Work on this is tracked here.
Requirements
InvenioRDM v12 requires:
- Python 3.9, 3.11 or 3.12
- Node.js 18+
- PostgreSQL 12+
- OpenSearch v2
Support for older versions of Elasticsearch/Opensearch, PostgreSQL and Node.js has been phased out.
Questions
If you have questions related to the InvenioRDM v12.0 release, don't hesitate to jump on Discord and ask us!
Credit
The development work of this impressive release wouldn't have been possible without the help of these great people:
- CERN: Alex, Anna, Antonio, Carlin, Fatimah, Javier, Jenny, Karolina, Lars, Manuel, Nicola, Pablo G., Pablo P., Pablo T., Yash, Zacharias
- Northwestern University: Guillaume
- TU Graz: Christoph, David, Mojib
- TU Wien: Max
- Uni Bamberg: Christina
- Uni Münster: Werner
- Front Matter: Martin
- KTH Royal Institute of Technology: Sam
- Caltech: Tom
Conference Spotlight: InvenioRDM Workshop Day at Open Repositories 2024

The 19th annual Open Repositories conference took place June 3 - 6, 2024 in Göteborg, Sweden. Attendees benefitted from hundreds of presentations on innovations in the world of digital repositories, all focused around this year's conference themes of Community, Transparency, and Sustainability. In addition, ten workshops were presented on June 3rd, the InvenioRDM Workshop being one of only two to receive a full-day allotment.
At our third annual OR InvenioRDM Workshop, over a dozen of our community members collaborated to present and discuss the software, and to showcase features and customizations currently in place at our own institutions. These include:
- Caltech's guide to customizing templates, vocabularies, and the deposit form
- NYU's multiple storage configuration
- University of Bamberg's UI-customizations, custom subjects and vocabularies, and deployment concept
- TU Wien's innovations on authentication and digital preservation
- University of Münster's use of Devbox to provide a streamlined InvenioRDM installation and development experience
- Northwestern University's implementation of Signposting in InvenioRDM
- CERN's demo of the Zenodo and CDS installations, as well as a v12 features demo
- KTH Royal Institute of Technology's customizations of InvenioRDM
In the afternoon, we offered two separate tracks. In the first we hosted self-organizing technical discussions, including a hands-on demonstration of Devbox presented by project partners from Uni Münster. We also encouraged participants to install InvenioRDM on their machines with help from technical experts, many of whom had already spoken in the earlier showcase session.
In the second track, we focused on community discussions with two additional presentations:
- The InvenioRDM Community: what it is and how to join
- Supporting Transparency and Compliance with InvenioRDM, a presentation from Northwestern on how InvenioRDM's features support compliance with the increasing number of public access and data sharing requirements for researchers
An informal survey of our 30+ participants afterward revealed that the workshop was generally very favorably received. Participants enjoyed the general introduction to the platform, as well as feature demonstrations and the opportunity to speak with members of the community. While some participants found installation challenging, others found deployment easy. Overall, participants found the experience to be valuable, with some encouraging us to offer the workshop again next year with minor tweaks.
Our active community participated in more than just the InvenioRDM workshop, however. Project partners also participated in:
- The Repository Rodeo: Alex Ioannidis on behalf of Zenodo
- A Data Repositories and Lessons Learned presentation from KTH on the KTH data repository based on InvenioRDM
- An outline of Zenodo's role in the Generalist Repository Ecosystem Initiative, presented by Northwestern University, in Empowering Global Progress: GREI Coopetition's Role in Standardizing Transparency, Community, and Sustainability Initiatives
- 24x7 session on Integrations for Sustainability and Transparency: NYU's presentation We Can Work It Out: Cross-Functional Collaboration on Repository Strategy
- A Developer Track session, Repositories and Computation: Crossover Episode presented by TU Wien
At the end of the conference, it was announced that the next Open Repositories will be hosted in Chicago from June 15 - 18, 2025. We will aim to host an InvenioRDM workshop once again, and we hope to see you there!
InvenioRDM Partner Meeting / Developer Workshop: Action Items

From March 18 - 22 the InvenioRDM partner community met in Münster, Germany, to discuss current challenges and plans for the future of the project. While many smaller questions and issues were addressed immediately on-site, e.g. during one of the “merge parties” or in work sessions resulting from and building upon previous discussions, many sessions ended with clear lists of planned actions for the coming weeks and months.
To showcase the kinds of actions we decided on, and to have something to measure our success by at the next developer workshop, we're sharing here our full list of action items. In the fall, approximately at the half-way-point between the last and the next workshop, the community will meet at a themed Telecon to evaluate this list and see what the status on these plans is.
In the following you can find a list of all sessions and the actions decided upon by the participants. Some of the plans mentioned were already set into action - a huge thank you goes to the motivated community members working on all these actions!
Community engagement and handling pull requests
- document this process in invenio-docs (curator role, responsibilities, templates, schedule, reviewer guide)
- make PR checklist more extensive (criticality, bug/feature, packages impacted, target release (old, current, new brach))
- merge party this afternoon and on a regular basis
- dream parties (form pitch to architecture proposal, mockups)
- demo parties
- public documentation of people to talk to for packages and features (e.g. list of module maintainers)
- dedicated role for community contribution management
- identify people involved from the community and their involvement (e.g. searchable expertise board)
Translations / i18n, i10n
- test if yaml-files can have four letter codes
- group tests Münster approach way of overwriting python strings, java-script
- Zack and David try to implement the Münster approach into the official cookiecutter so its easier to use and has a global storage of frontend translations
Large file management
- Multipart uploader
- File linking API
- File metadata
Invenio RDM Version 12
- fix the blockers until end of April
- document features
- translate in May
- going forward and release v12 before open repositories
Invenio CRIS
- further call for interest in InvenioRDM visio conferences (presentation)
- Created a GitHub Discussion to gather more use cases and interest from the community inveniosoftware/product-rdm#153
- decide between specific in communities and more ambitious in a specific module based on traction
- If invenio-communities is the way to go, try to put specific fields in community data model in a bucketed way
- deepen code review
Customising Schema
- Write a feature request for overlay config for required fields per instance / community.
- Improve docs on Custom Fields - checklist on when they're useful, community examples.
- Case studies / knowledge sharing of the 'hard way' customisations that have been achieved.
Deployment
- do a Session on small one VM deployments
- do a Session on Helm charts
- update deployment documentation
Digital Preservation
- Brush up Invenio-SIPStore (Max) Check out Invenio-Archivematica, or look at the AM Python client (Max) Check if an AM plugin for Invenio is needed (Panna?)
Workflow to keep internal roadmap updated
- GitHub Discussions implemented for feature request forum
- CERN will do quarterly cleaning & updates of roadmap items (Jan, Apr, Jul, and Oct) and will host talks about issues at corresponding Telecons
RDM Curation Workflow
- open question is if/how this could go into the core or if it should remain an extra package maintained by TU Graz
- ensure possibility to configure aspects in order to meet discussed requirements, use cases, and user stories
- upload package to GitHub for future collaboration
- after follow-up discussion, one idea is to extend the functionality of the requests in the core and build the curation on top of these changes
- more details
- Split approval and acceptance of requests
- Requests can be extended with requirements/checks. These have to be fulfilled before a request can be accepted.
- Can be specified per request type
- Repository wide requirements are applied to all request types
Harvesting vocabularies
- Start a coordinated sprint in May (CERN and Uni Münster).
Creating a place to collect Invenio modules etc.
- Awesome Invenio - links to the actual GitHub Repository where everyone with a GitHub account can add their or other projects and create a PR for it. It's mainly curated by @egabancho for the time being.
Community workflow improvements
- Pitch governance documentation update
- Propose group structure (InvenioRDM Interest and Task Groups)
- Propose new/additional way of subscribing to the list-serv
- Pin and list welcome message and resource list to the welcome channel in Discord
Developing with Devbox
- share repository with all used scripts with community
Repeatable installs
- always copy
package-lock.jsonfrom../var/instance/assets/tomy-site/. Make sure thatgitignores the creation/modification file dates if the file content didn't change - have an extra CLI param in
invenio-clithat will:- copy the
package-lock.jsonfrommy-siteto../var/instance/assets/ - if the
my-site/pipfile.lockis newer thanmy-site/package-lock.json, then overwrite or fail (some python deps might have changed) - run
npm ciinstead ofnpm install
- copy the
- the development workflow with linked editable (watched) modules should be tested, to ensure nothing breaks
- when in
NODE_ENV=production, the above should always happen. When inNODE_ENV=dev, then I can use a new paraminvenio-cli install --keep-deps - New issue tracked here: inveniosoftware/product-rdm#179
One VM Deployment
- improve documentation with the deployment
- cookiecutter issue: inveniosoftware/cookiecutter-invenio-rdm#278
- have a finished docker-compose without dev container
- improve secrets by default
Preservation of workshop outcomes
- Create a Google form for filling in session information (→ Steve)
- Process information from the Google form entries (→ Markus)
- Create a repo in the inveniosoftware namespace (→ someone from CERN)
Kubernetes Helm-charts requirements
- Issues on the
[helm-invenioGithub repo](https://github.com/inveniosoftware/helm-invenio/issues) - Share of current community charts:
- University of Münster:
helm pull oci://harbor.uni-muenster.de/ulb/invenio --version 0.4.0
- University of Münster:
Workgroup structure - Governance
- please contact Lars if you know a good mailing list software! - in progress
InvenioRDM feature request form
- GitHub Discussions feature request forum implemented
Usage statistics
- Created discussions
Evaluate proposed strategies for handling PRs
- regular merge parties right after Telecons (cut Telecons to 30 minutes) (Sara)
- train more people as maintainers with merge rights (in on-site meetings) (CERN)
- figure out a clear labeling system (Karolina)
InvenioRDM Partner Meeting Summary, March 2024

The InvenioRDM partner community met in Münster, Germany from March 18 - 22, 2024, for our first in-person annual meeting in over four years. Forty-six attendees from over fifteen institutions spent the five days making connections, planning, and diligently working on all things InvenioRDM.
Organizer Sarah Wiechers, software developer and research data manager for the Service Center for Data Management, ULB Münster, proposed the use of Open Space Technology, a meeting organization methodology in which the agenda and topics discussed are voted upon and implemented by the meeting’s attendees on the meeting date. This methodology was highly effective, allowing all community members the opportunity to pitch ideas and vote on their favorites for discussion.
University of Münster’s InvenioRDM Community GitHub site contains our full output of discussions, decisions, and plans. Key topics addressed were the timely handling of pull requests, planning for the v12 release, improvements to community workflows, translations, large file management, deployment, digital preservation, vocabularies and fixtures, Kubernetes Helm-charts requirements, and much more. To help manage feature requests going forward, we have agreed to implement GitHub Discussions, a tool which will allow for providing context, asking questions, and upvoting most-wanted features. GitHub Discussions is now part of our workflow for keeping the Roadmap updated.
We were thrilled to be able to work with so many old and new friends in beautiful Münster, and a huge thanks goes to our local hosts at University of Münster for their hard work and hospitality. We hope that you will be able to join us at next year’s meeting, with Hamburg currently slated as the host city. In the meantime, please take advantage of our following updated community workflows, including:
- Development-focused chats during half of each telecon
- A new email list - coming soon
- Newly established Interest Groups (long-standing) or Task Groups (deliverable-focused). For the current list of all Groups, see the new Onboarding page
Prism: The New Feinberg Repository for Global Dissemination of Research

The Prism institutional repository has launched at Northwestern University. Prism preserves and makes available articles, conference presentations, preprints, datasets, and other items created by faculty, staff, and students. Prism helps openness, maximizes reproducibility, and enhances research connections within Feinberg School of Medicine and across the globe.
Prism replaces the former DigitalHub and includes many much-anticipated features, such as the ability to create metadata-only records for offsite datasets, set embargo dates for releasing content to the public, create and curate communities of practice, and share private links to view and edit with colleagues. These new features complement existing features such as the ability to assign Digital Object Identifiers that make records citable, indexing by Google to make research widely discoverable, and a responsive staff at Galter Library to answer questions and provide support.
Kristi Holmes, the Director of Galter Health Sciences Library, Associate Dean of Knowledge Management and Strategy, and professor of Preventive Medicine, played a leading role in the development of Prism. According to Holmes, “It is essential to have a robust institutional repository that can keep up with the latest technologies and trends. As models for open access and data sharing continue to evolve, it's clear that institutional repositories will play an increasingly critical role to make research Findable, Accessible, Interoperable, and Reusable (FAIR).” She continues, “What makes this project particularly special is the strong collaborative approach we’ve taken both at Northwestern and also in partnership with the larger open source community. I’m grateful to our team at Galter Library for their incredible work.”
“We are excited to announce the launch of Prism as the institutional repository for Feinberg School of Medicine” says Karen Gutzman, Head of Research Assessment and Communications at Galter Health Sciences Library and Learning Center. Prism builds on a strong research foundation first made possible in the DigitalHub repository. “One of the most exciting features of Prism is the ability to create communities on topics, projects, or events” says Gutzman. Communities include open access research from Feinberg on COVID-19, training presentations from the Biostatistics Collaboration Center, and the NUCATS Grant Repository, a centralized resource for grant writers and investigators internal to Northwestern provided by the NUCATS Institute. “Prism is an excellent home for the NUCATS Grants Repository, allowing us to easily share exemplar grant templates and other resources with investigators across the Northwestern University community,” says Dr. Richard D’Aquila, Director of NUCATS.
Prism is built on the InvenioRDM software, which also forms a strong and sustainable foundation for Zenodo. “With its user-friendly interface and advanced features, InvenioRDM is truly a game-changer in the world of repositories. This platform is designed to make research more accessible and open to the public, promoting innovation and collaboration within the academic community,” says Holmes. Over the past several years, CERN and Northwestern have collaborated as core co-developers of the software, partnering with the global Invenio Open Source Community to develop InvenioRDM as a turnkey, scalable, and top-of-the-class user experience software for repositories. The InvenioRDM software offers a reliable environment for science, empowering preservation, credit, discovery, and sharing while maintaining integrity in its responsiveness to the evolving needs of the research community, including data sharing policy compliance. Northwestern contributions to the open source project are led by Matt Carson, Senior Data Scientist and Head of the Galter Library Digital Systems Department, with developer Guillaume Viger leading technical work and Sara Gonzales, Senior Data Librarian at Galter Library, contributing to a wide range of efforts, including serving as the Community Manager.
Notably, Northwestern and CERN recently expanded this collaboration through an award from the NIH Office of Data Science Strategy/Office of the NIH Director pursuant to OTA-21-009, Generalist Repository Ecosystem Initiative (GREI), to Zenodo to help researchers improve discoverability of their data and lead to greater reproducibility and reuse of data. Through this award and others, the infrastructure reflects Desirable Characteristics of Data Repositories for Federally Funded Research and continues to evolve to meet research needs and support a vibrant data ecosystem.
Conference Spotlight: InvenioRDM Workshop Day at Open Repositories 2023

Last month InvenioRDM project partners convened in Stellenbosch and Cape Town, South Africa for the 18th International Open Repositories Conference (OR2023). We were thrilled to offer our second InvenioRDM workshop on the 12th of June (see our wrap-up of the first workshop: OR2022 workshop). During three eventful hours we spoke with librarians, data managers, administrators, and developers about the basics of joining the InvenioRDM project and standing up an instance. We also shared information on customizations and add-ons for those interested in the platform’s advanced capabilities.
Following Nicola Tarocco’s introduction and demo of key InvenioRDM functions and features, our sessions included:
- Maximilian Moser’s presentation on customizations for his local InvenioRDM instance TU Wien Research Data, as well as a CLI command enabling very large file upload
- Dan Granville’s presentation on IIIF in InvenioRDM, exemplified through his work with Data Futures GmbH
- Guillaume Viger’s presentation on the launch of Northwestern University’s Prism instance, with a particular focus on successful migration of awkward data
- Matt Carson’s presentation on InvenioRDM’s support of the FAIR principles, with additional information on the platform’s support for data policy initiatives
- Maximilian and Guillaume’s presentation on the details of, and endless possibilities for, deployment of InvenioRDM instances
- Zacharodimos Zacharias’ presentation on his and the CERN team’s iterative and productive efforts to achieve fast and efficient data migration as a test for Zenodo’s move to InvenioRDM later this year.
The workshop attendees were engaged, brought great questions, and gave us much food for thought. Our conversations with potential new partners were so extensive that we were not able to include all planned presentations! Be on the lookout for future blog posts containing this bonus content.
But wait, there’s more! InvenioRDM’s OR2023 representation included Nicola’s fantastic lightning talk on behalf of InvenioRDM in the annual Repository Rodeo. In addition, Maximilian Moser and David Eckhard of TU Graz presented their work on a communication protocol to connect machine-actionable DMPs with InvenioRDM, and Zacharodimos Zacharias presented on InvenioRDM’s mature integration with ROR (the Research Organization Registry).
All of the InvenioRDM Workshop Day presentations are now available for download from Zenodo. We hope to host another InvenioRDM workshop at the 19th Annual Open Repositories Conference June 3-6th, 2024 in Gothenburg, Sweden. If we’ve missed you at our previous two workshops, we hope to see you there!
Introducing the InvenioRDM GitHub Archiver (IGA)
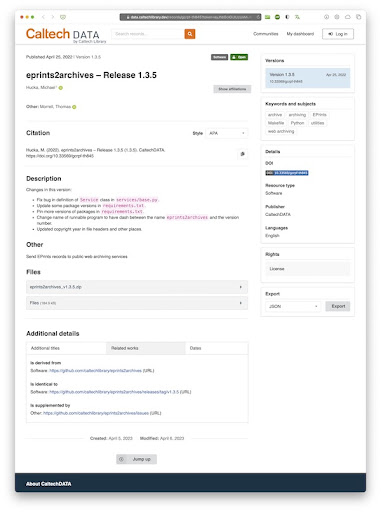
The InvenioRDM GitHub Archiver (IGA) is a new software tool created by the Caltech Library. InvenioRDM is the basis for many institutional repositories, such as CaltechDATA, that enable users to preserve software and data sets in a long-term archive. The metadata contained in the record of a deposit is critical to making the record widely discoverable by other people. However, creating detailed records and uploading assets can be a tedious and error-prone process if done manually. This is where our new tool comes in.
IGA creates metadata records and sends releases automatically from GitHub to an InvenioRDM-based repository server. It constructs a metadata record using information it gathers from the software release, the GitHub repository, the GitHub API, and various other APIs as needed. Here are some of IGA’s other notable features:
- Automatic metadata extraction from GitHub releases, repositories, and
codemeta.jsonandCITATION.cfffiles - Thorough coverage of InvenioRDM record metadata using painstaking procedures
- Recognition of identifiers that appear in CodeMeta and CFF files, including ORCiD, ROR, DOI, arXiv, and PMCID
- Automatic lookup of publication data in DOI.org, PubMed, Google Books, & other sources if needed
- Automatic lookup of organization names in ROR (assuming ROR id’s are provided)
- Automatic lookup of human names in ORCiD.org if needed (assuming ORCID id’s are provided)
- Automatic splitting of human names into family and given names using ML-based methods if necessary
- Support for record versioning
- Support for InvenioRDM communities
- Support for overriding the metadata record IGA creates, for complete control if you need it
- Ability to use the GitHub API without a GitHub access token in many cases
- Extensive use of logging so you can see what’s going on under the hood
Data and software archived in a repository need to be described thoroughly and richly cross-referenced in order to be widely discoverable by other people. Of particular interest to software developers is that a repository like CaltechDATA offers the means to preserve software projects in a long-term archive managed by their institution. IGA helps make the creation of metadata and InvenioRDM records for software and data managed in GitHub as easy as possible.
More information about the InvenioRDM GitHub Archiver is available at caltechlibrary.github.io/iga/.