Whoops! The Better-Late-Than-Never March 2025 InvenioRDM Partner Meeting Summary

As the InvenioRDM partners were making their way back home from 2026's annual partner meeting, we suddenly realized we had not published a blog post summarizing 2025's partner meeting. Whoops! Turns out, we were so busy building and improving InvenioRDM for you that it completely slipped our minds. Before we catch you all up on the most recent meeting, here is a summary of the great things that the InvenioRDM partners accomplished in 2025.
Meeting highlights
Kai Wörner, Deputy Head of the Center for Sustainable Research Data Management at Universität Hamburg, and his team, hosted the InvenioRDM community for five days from March 24 - 28, 2025. In addition to the local team's hospitality, participants experienced the university's cutting-edge research and the city's rich maritime heritage, cultural diversity, and the enchanting Miniatur Wunderland. Meanwhile remote participants enjoyed a seamless experience through a Zoom/Owl setup provided and maintained by Steve Diggs, an InvenioRDM collaborator currently with the Scripps Institution of Oceanography.

Instance rodeo & Open space technology
The first day was devoted to an "InvenioRDM-Instance-Rodeo," in which maintainers of local instances showcased their implementations, sharing their local innovations and customizations.
Next, utilizing proven methodology, Open space technology was used to enable participants to propose and vote upon topics for discussion. The topics included:
- Glacier/cold storage handling
- Full-text search
- Automated metadata extraction from files
- User experience on the deposit form
- EduGAIN interfederation
- Accessibility issues
- Self-contained HTML reports
- RO Crate previews
- Invenio-stats
- Translations
- Thesis Fields
- Scope of the Partner Meeting and Community topics
- Maintainers playbook
Tangible outcomes
A few of these topics have had concrete effects visible today, including:
- The deposit form now offers enhanced customizability, allowing users to hide or show fields, reorder components, and easily locate elements for override.
- Available metadata fields have been expanded to include new optional fields, such as thesis, improving content description and FAIR compliance.
- Joining the maintainers team is now more accessible with the introduction of the new Maintainers Handbook.
- Partner Meeting structure decision: maintain the first two days for presentations and general information so those considering the software can attend just the first 1-2 days for a general overview.
Thanks
Many instance presentations from the Rodeo can be viewed in the InvenioRDM Partners Workshop 2025 Zenodo community. Many thanks to the local hosts at Universität Hamburg for their hard work and hospitality, and thanks also to Steve Diggs!
Repositories and libraries: Invenio features InvenioILS!
For years, the Invenio community has been known for powerful open-source repository solutions - especially InvenioRDM. But many institutions need more than a repository: they need a modern, flexible platform that also supports collections, loans, acquisitions, and patron services.
InvenioILS brings these capabilities into the Invenio family, offering a fully open, customizable Integrated Library System built on the same modular framework as InvenioRDM.
A modern, feature-rich ILS (Integrated Library System)
InvenioILS delivers the essential tools libraries rely on:
- Circulation & patron services: loans, renewals, requests, notifications, and configurable policies.
- Cataloguing & metadata: flexible JSONSchema-based records, holdings, items, and fast discovery powered by Elasticsearch/OpenSearch.
- Acquisitions & ILL: vendor management, orders, budgets, document delivery, and interlibrary loan workflows.
- Clean, responsive UI: a modern interface designed for both librarians and patrons.
Flexible and extensible by design
InvenioILS is highly modular and, like InvenioRDM, based on Invenio Framework. It becomes easier to share the expertise between these two products. Institutions can customize metadata, circulation rules, UI components, and system behaviour - or integrate with external services through the REST API. This flexibility allows libraries to adopt InvenioILS “as is” or tailor it into a specialized solution that fits their workflows and identity.
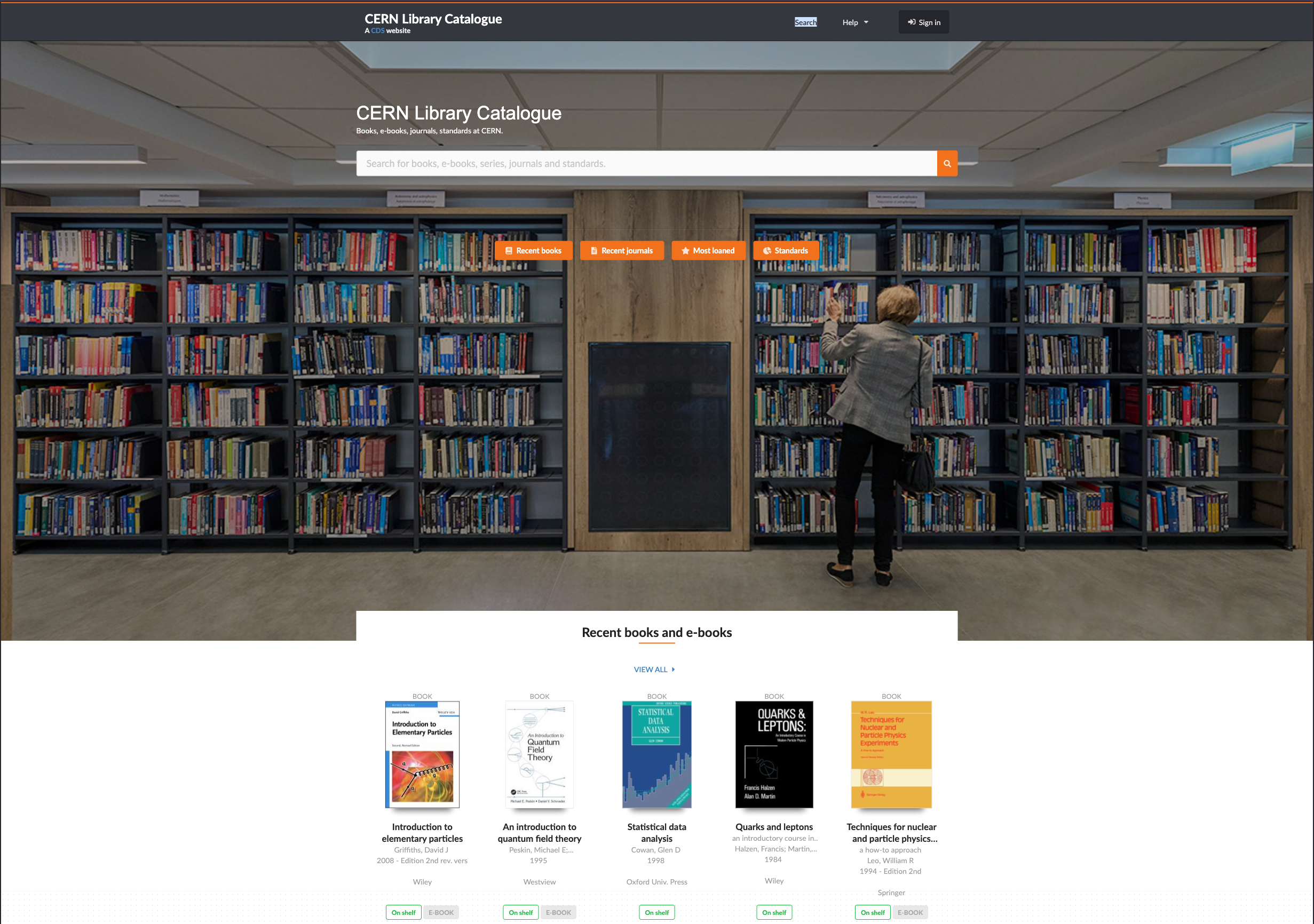
CERN: A Showcase Installation
An example of an advance deployment of InvenioILS is at CERN - CERN Library Catalogue, where the platform powers daily library operations and serves thousands of users.
Smooth SSO integration
InvenioILS connects seamlessly to CERN’s institutional Single Sign-On, providing automatic user provisioning, role synchronization, and a unified login experience across CERN services.
Bulk e-book importer (CERN customisation)
CERN uses an automated bulk importer to process large vendor MARC packages. Metadata is transformed, validated, and ingested with minimal staff intervention - turning what once took days into an efficient, scalable workflow.
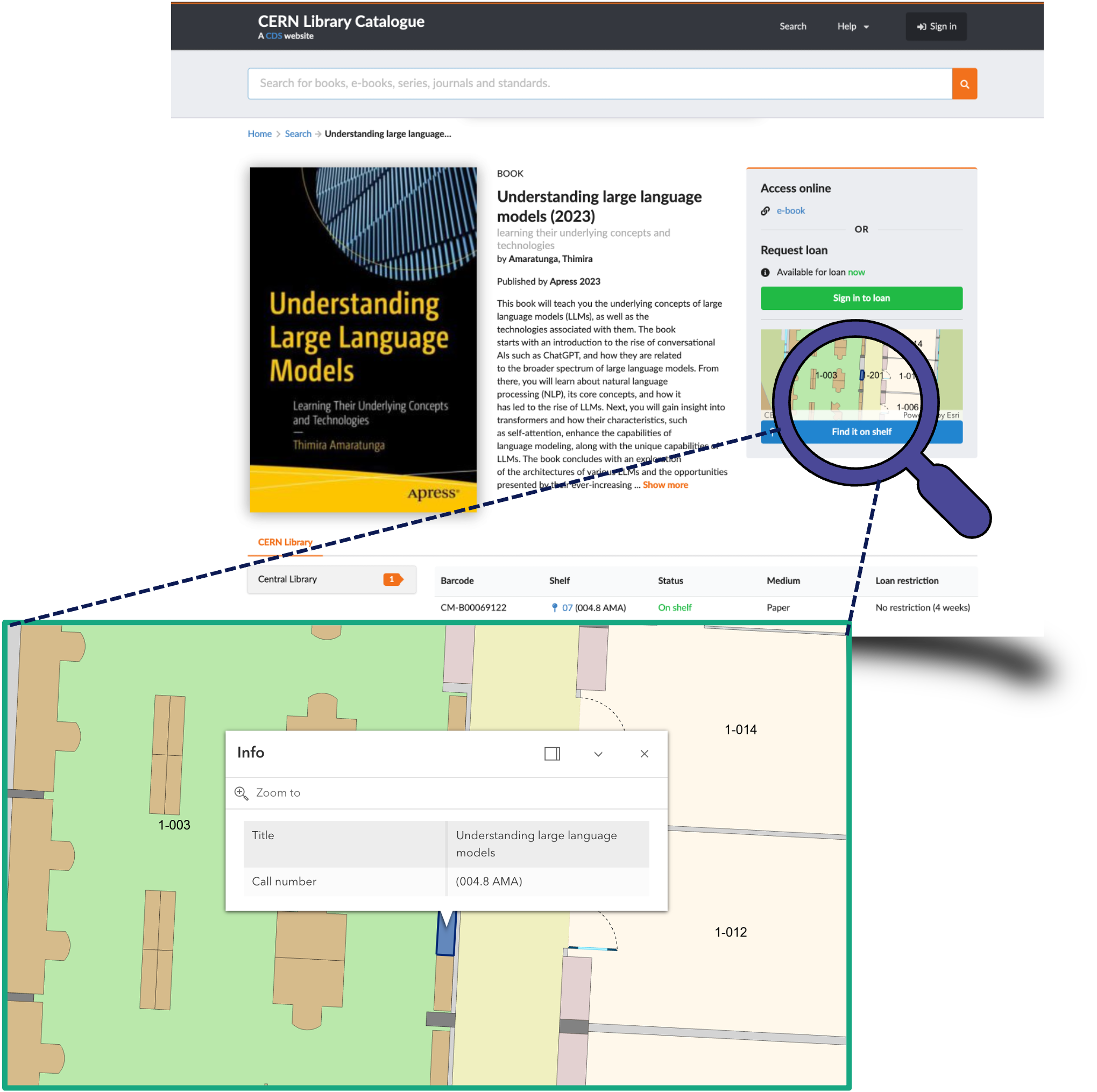
Mobile self-checkout & campus navigation (CERN customisation)
CERN’s library offers mobile self-checkout, enabling patrons to borrow items directly from their phones. Through InvenioILS APIs, the system also integrates with CERN’s internal navigation app, guiding users to shelf locations and showing real-time item availability.

Reliable at scale
The CERN installation demonstrates how InvenioILS can support large user bases, extensive collections, and demanding operational environments - all while integrating with CERN Institutional repository, based on InvenioRDM.
Part of a product family
InvenioILS complements InvenioRDM and the broader Invenio framework, providing a cohesive platform for managing both library collections and research outputs. With shared components and infrastructure, institutions benefit from consistent authentication, indexing, APIs, and development practices across products.
Invenio does not only power repositories.
It powers libraries as well - with power of Free Open-Source Software
Join the Invenio community
InvenioILS and InvenioRDM thrive thanks to a global community of libraries, research organizations, developers, and service providers. Whether you’re evaluating Invenio, looking to contribute, or simply curious, you’re warmly invited to join. The InvenioRDM community meets regularly to discuss features, share insights, and collaborate on the future of open knowledge systems - we would like to recreate this approach for InvenioILS and hear your feedback. Your voice is welcome - come help, shape what’s next.
datasafe: Implementing a Dark Archive with InvenioRDM
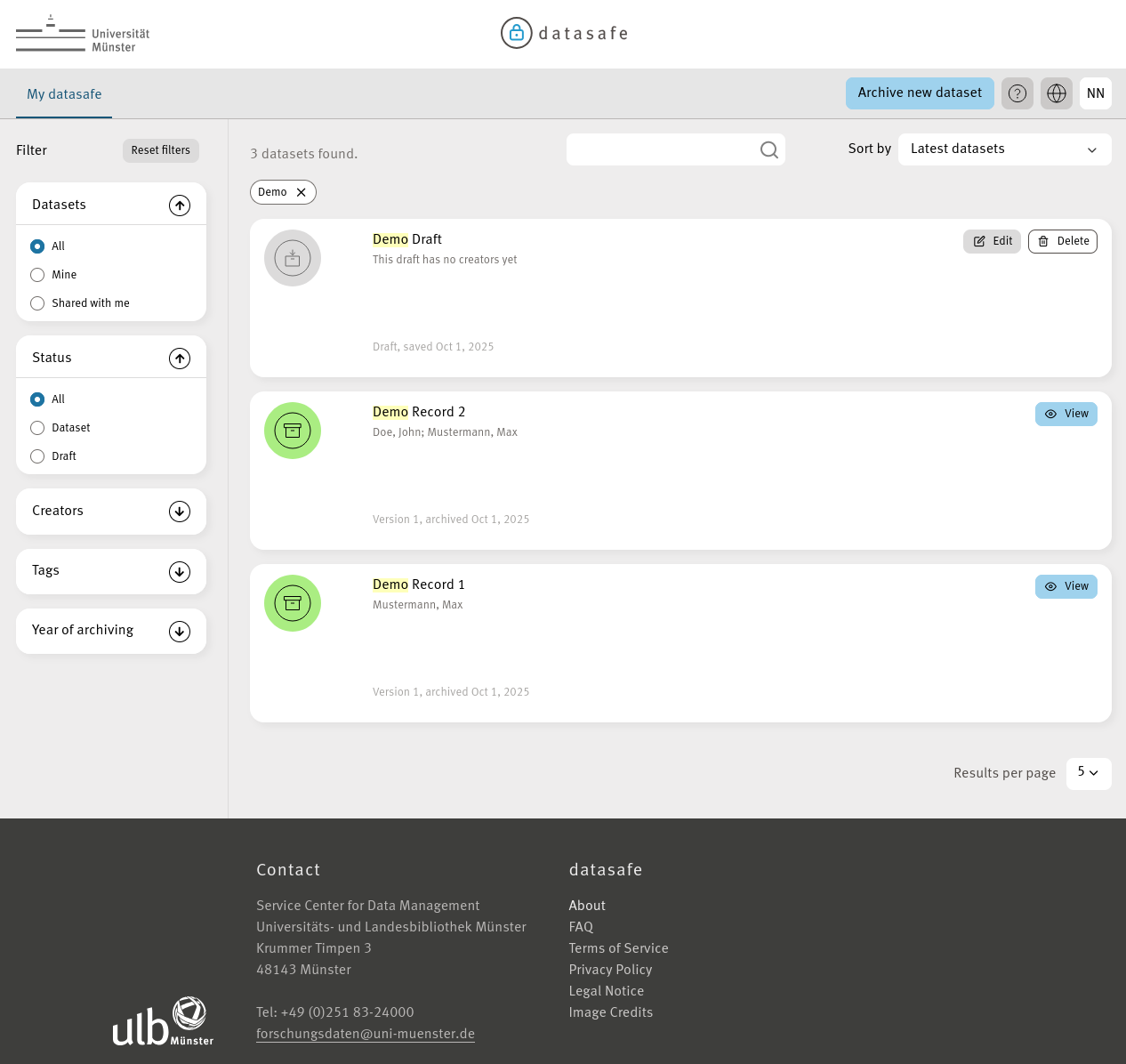
We've recently completed a major overhaul of our research data archive, datasafe, which is now built on InvenioRDM. Our team at the University of Münster's University and State Library (ULB) has been working to implement this open-source software, tailoring it to meet the specific needs of our researchers.
datasafe is designed as a dark archive, where researchers can deposit their datasets for long-term preservation. Once archived, the data will be retained for a minimum of 10 years, and up to 15 years, after which it will be automatically deleted. To streamline the process, metadata can be easily imported from our local Current Research Information System (CRIS).
One of the key benefits of using datasafe is the ability for researchers to demonstrate compliance with funder requirements for data storage. Upon archiving their data, users receive a certificate that confirms their datasets have been securely stored, making it easier to report to funding agencies.
A notable feature of our implementation is the heavily customized frontend, which provides a minimalist and modern interface. By simplifying the user experience, we've created an intuitive platform that meets the unique needs of a dark archive, where data is primarily stored for preservation purposes rather than dissemination. This approach allows researchers to easily deposit and manage their data, while also ensuring the long-term integrity and authenticity of the archived materials.
Another significant improvement is the increased upload limit, now up to 5 TB in size. This community-driven feature, which our team helped implement, enables researchers to upload large files directly through their web browser into the underlying S3 storage backend, eliminating the former need for an SFTP server. This will greatly benefit researchers working with large datasets, allowing them to archive and preserve their data in a single, convenient location.
By building on InvenioRDM, we're able to leverage a community-driven solution that is actively maintained and developed by a global network of institutions and experts. We're pleased to be part of this community and look forward to sharing our experiences and feedback to help shape the future of the platform.
For those interested in learning more about our implementation of InvenioRDM, you can contact our team at forschungsdaten@uni-muenster.de!
Ensuring the Future of Digital Repositories in West and Central Africa: A Case Study on BAOBAB and Sustainable Repository Development

In today’s rapidly digitizing research landscape, the ability to preserve and share knowledge openly is not just a technological challenge, it’s a matter of equity and innovation. Yet, across much of West and Central Africa, many institutions still struggle with inadequate infrastructure for digital preservation. As I shared at a recent OR2025 session, this is where BAOBAB comes in.
Why Repositories Matter
Open Access repositories are critical tools for fueling collaboration, driving innovation, and reducing information inequality. But for many African universities and research centers, significant barriers, from unreliable digital systems to a lack of preservation strategies, hinder their ability to contribute to and benefit from the global research ecosystem.
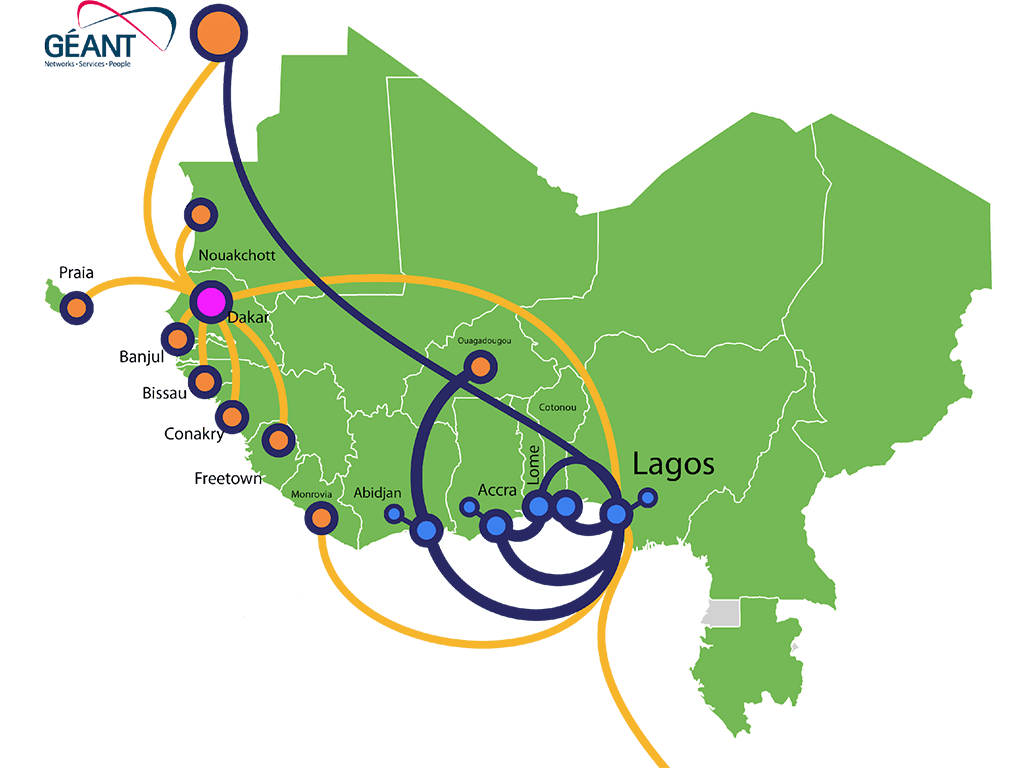
Introducing BAOBAB
Launched in 2024 by WACREN, the West and Central African Research and Education Network, BAOBAB is an InvenioRDM-based regional repository service designed to close these gaps. As of now, it supports more than 14 institutions across 8 countries, including public universities, research councils, and technical institutes. What sets BAOBAB apart is its ability to offer a centralized infrastructure while preserving local institutional autonomy, a model that ensures scalability without sacrificing ownership.
Tackling the Challenges
Before BAOBAB, institutions operated in silos. Many lacked reliable backup systems, and technical capacity varied widely. This often led to duplicated efforts and even loss of valuable data. BAOBAB’s shared, cloud-based platform reduces the technical burden for individual institutions, while a community-driven governance model ensures the service evolves with user needs.
What’s Inside the Repository?
BAOBAB has quickly become a treasure trove of African research. From PhD theses and conference papers to datasets, the repository ensures materials are enriched with multilingual metadata and accessible through persistent identifiers. That last point is key.
Why ARKs?
BAOBAB adopts ARKs (Archival Resource Keys) as its persistent identifier system. Why? Because they’re:
- Cost-effective and flexible
- Free from vendor lock-in
- Interoperable with existing and future PID systems
Each item in BAOBAB automatically receives an ARK, ensuring it can be reliably found and cited over the long term.
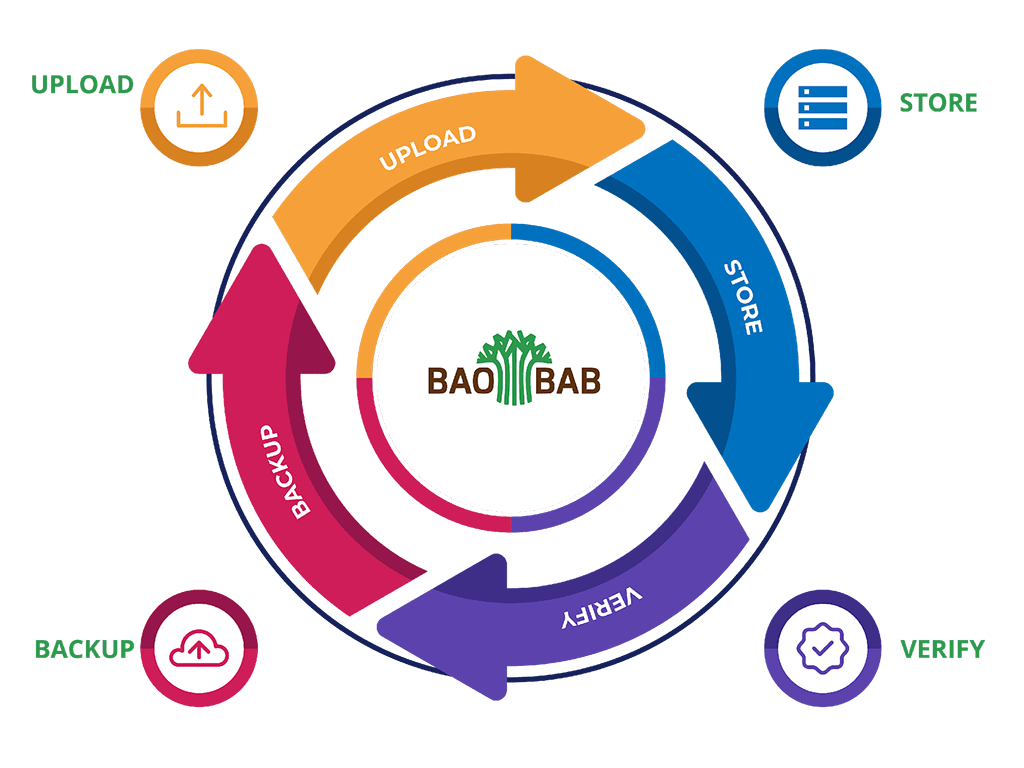
Building for the Long Run
But identifiers alone don’t guarantee preservation. BAOBAB is developing a comprehensive digital preservation strategy, including:
- A formal preservation policy
- Offsite backup strategies
- Regular file fixity checks
- Compliance with international metadata standards
These efforts aim to make the repository resilient, even in the face of funding or infrastructure challenges.
Learning from Global Peers
BAOBAB didn’t start from scratch. It was inspired by global leaders in repository development, including:
- LA Referencia in Latin America
- HAL in France
- The Africa Open Science Platform
These models were carefully studied and adapted to local realities—proving that global solutions can be tailored to local contexts.
Measurable Impact
Since its launch, BAOBAB has archived over 408 documents, reduced duplication across participating institutions, and improved the visibility of African research on a regional and international scale. That’s not just a technical win, it’s a step toward equity.
A Blueprint for the Continent
BAOBAB is more than a platform, it’s a blueprint for sustainable repository development across the continent. It shows that with thoughtful design, community involvement, and the right infrastructure, even resource-constrained regions can lead in Open Access.

Final Thoughts
Sustainable, equitable, and locally owned repositories aren’t just possible, they’re essential. BAOBAB’s success offers hope and a roadmap for other regions aiming to strengthen their research infrastructure. At WACREN, we believe the future of African research lies in collaboration, openness, and resilience.
Let’s build it together.
![]()
InvenioRDM v13.0 released
We are excited to announce the release of InvenioRDM v13.0 on July 23, 2025! This new version brings a host of new features and improvements, building upon the strong foundation of previous releases.
Try it
Want to try the new features in v13.0? Just head over to the demo site. If you want to install it, you can follow the installation instructions.
Release Notes
See the full release notes for details on all the new features, and the upgrade guide for instructions on how to upgrade from your v12 instance to v13.
What's new?
InvenioRDM v13.0 focuses on enhancing administrative capabilities, improving community features, and introducing powerful new tools for data management and organization. Here are some of the major highlights, be sure to check the release notes for a comprehensive list of new features and improvements.
Communities enhancements
The Communities functionality has been significantly expanded with exciting new features:
Themed communities
Communities can now be customized with unique fonts, colors, and homepages. These themes apply to all community pages, including records and requests, allowing for a more branded and distinct user experience.
Subcommunities
InvenioRDM v13.0 introduces hierarchical relationships between communities through subcommunities. This allows for structured organization, where records from child communities are automatically indexed in parent communities. A dedicated "Browse" page lists subcommunities and collections, providing a clear overview.
Collections
Collections are a powerful new feature enabling dynamic, query-based groupings of records that automatically update. Collections provide dedicated pages for records matching specific criteria and can be organized hierarchically by subject, resource type, funding program, or other metadata fields. This is ideal for grouping content by research disciplines, publication dates, or funding programs.
Curation checks
It is now possible to configure automated checks in your communities to provide instant feedback on draft review and record inclusion requests. Checks provide feedback to both the user and reviewer that submissions to your community are compliant with your curation policy.

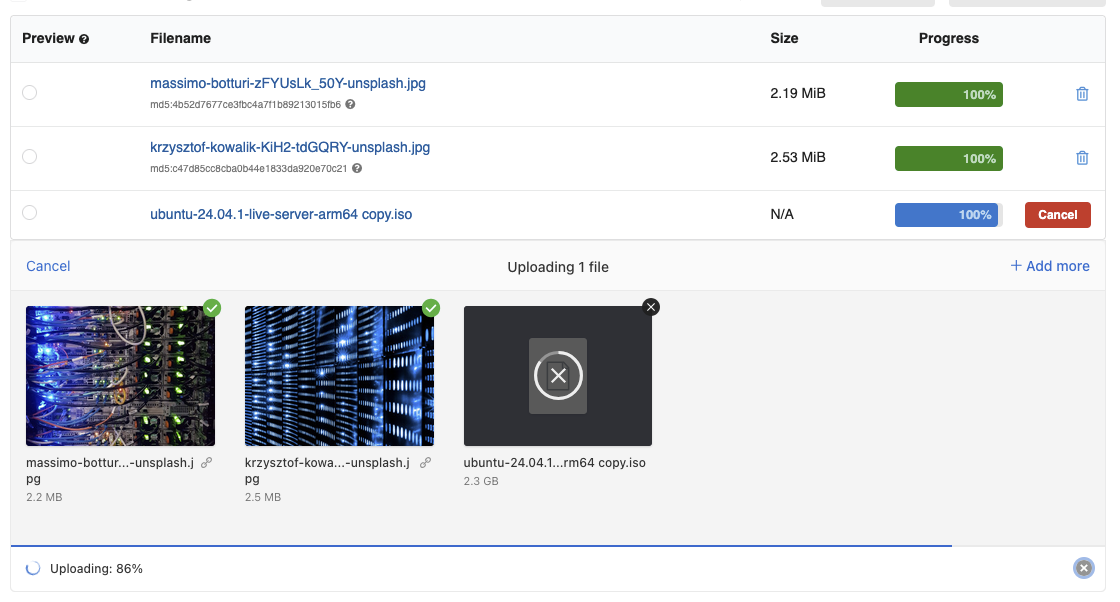
Files uploader & S3-compatible storage
The new file uploader delivers a faster, more intuitive, and modern file upload experience. It also enables advanced features such as multipart file transfers with S3-compatible storage backends.
FAIR Signposting
With v13, you can now enable support for FAIR Signposting level 1 in addition to the automatically enabled level 2.
Sitemaps
InvenioRDM v13 introduces the automatic generation of sitemaps to help search engines and other crawlers discover and index your repository's content. Sitemaps are even automatically linked in your robots.txt.
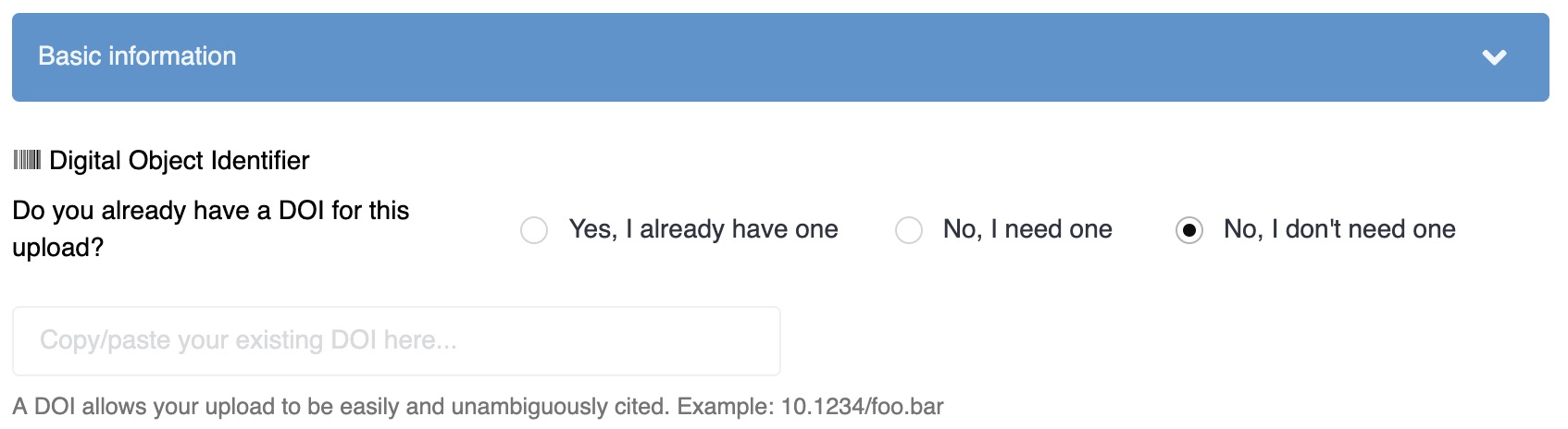
DOIs on demand
You can now let users to choose if they need a DOI or not when uploading.
New metadata fields
We have introduced new metadata fields that will allow you to capture more useful information when uploading:
- A dedicated copyright field is now available, ensuring clear and comprehensive copyright information.
- We've added a new Thesis set of optional metadata fields. We've also reorganized the thesis section, grouping thesis fields together.
- The edition field has been introduced under the Imprint set of optional metadata fields, providing a way to specify the edition of a book.
- A new identifiers field, composed of id and scheme, has been added to the Meeting set of optional metadata fields.
Dashboard: shared with you
You can now easily find records and requests shared with you.
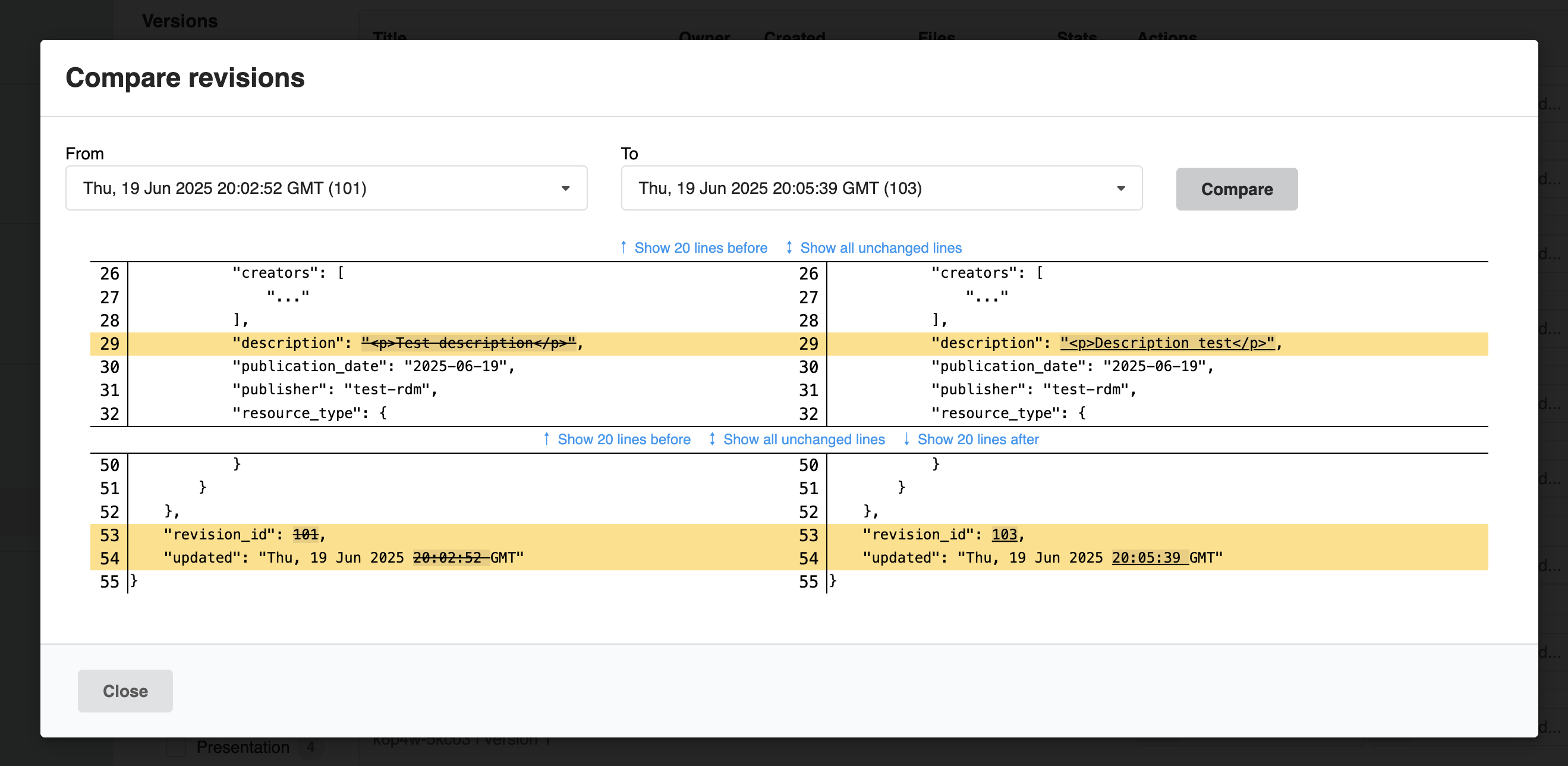
Compare revisions
A brand new compare revisions feature has been introduced, allowing administrators to audit record updates and track changes over time. This provides a transparent history of modifications, crucial for data integrity and compliance.
Audit Logs
A significant addition is audit logs, a new feature designed for tracking system activities and providing a detailed record of events accessible from the administration panel.
Jobs
This release introduces a new jobs feature, providing a comprehensive way to manage asynchronous tasks via the UI or REST API. Jobs are triggered via the admin UI or REST API, run using Celery, and support logging, argument validation, and result tracking.
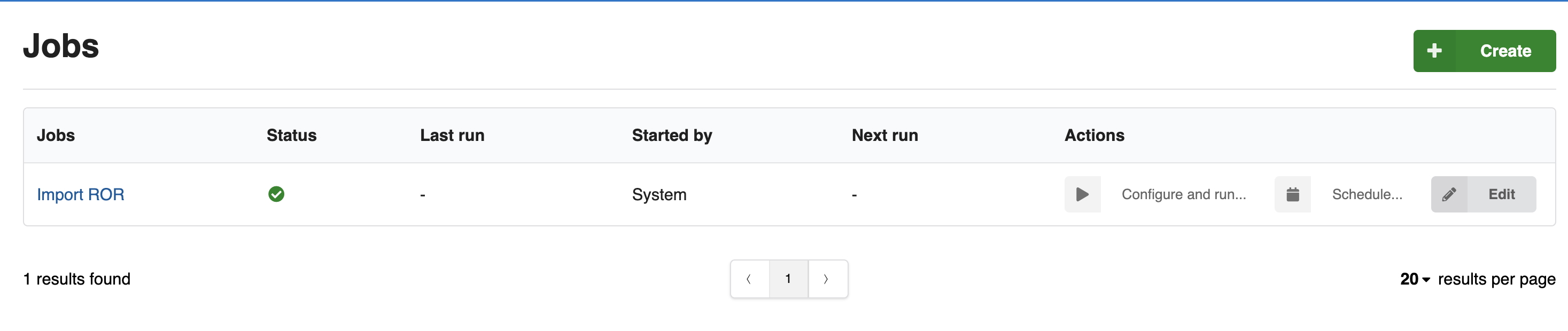
Jobs can be very useful to setup automatic recurrent fetching of ROR and ORCID databases or other vocabularies.
Breaking changes
Make sure to read the Breaking Changes section in the release notes.
Requirements
InvenioRDM v13 requires:
- Python 3.9 (end of life October 2025), 3.11 and 3.12
- Node.js 18+
- PostgreSQL 12+
- OpenSearch v2.12+
Questions
If you have questions related to the InvenioRDM v13.0 release, don't hesitate to jump on Discord and ask us!
Credit
The development work of this impressive release wouldn't have been possible without the help of these great people (name or GitHub handle, alphabetically sorted):
- Adrian Moennich
- alejandromumo
- Alex Ioannidis
- Alzbeta Pokorna
- Anika Churilova
- Austin Sharp
- Brian Kelly
- Carlin MacKenzie
- Christoph Ladurner
- Cristian Pogolsha MBP
- Dan Granville
- David Eckhard
- David Glueck
- ducica
- Eduard Nitu
- Emil Dandanell Agerschou
- Eric Newman
- Eric Phetteplace
- Esteban J. G. Gabancho
- Fatimah Zulfiqar
- Felipe Carlos
- Florian Gantner
- Furkan Kalkan
- Guillaume Viger
- Hrafn Malmquist
- Ian W. Scott
- Janne Jensen
- Javier Romero Castro
- Karl Krägelin
- Karolina Przerwa
- libremente
- liptakpanna
- Martin Fenner
- Martin Obersteiner
- Matt Carson
- Maximilian Moser
- mb-wali
- Michael Groh
- Mirek Simek
- Miroslav Bauer
- mkloeppe
- Nicola Tarocco
- Pablo Panero
- Pablo Saiz
- Pablo Tamarit
- Panna Liptak
- roll
- Saksham Arora
- Sam Arbid
- Sarah Wiechers
- Tom Morrell
- Werner Greßhoff
- Will Riley
- Yash Lamba
- Zacharias Zacharodimos
KTH Data Repository: Launching an InvenioRDM-based Institutional Repository
KTH Data Repository - we added user guides and updated the KTH web-pages on research data management when the new repository was launched.
On the 29th of January 2025, the KTH Data Repository was launched through a team effort supported by management and policies at the KTH Royal Institute of Technology, and by partnering up with the InvenioRDM community.
A Bit of History Behind the Launch
Back in 2021, KTH had an institutional repository for publications, theses, and student reports, but no repository for research data. A recently established cross-functional research data team offers curation support for researchers depositing data to either a KTH community in Zenodo or the Swedish National Data Service data catalog, DORIS. But we had challenges the services at the time didn’t meet:
- Researchers often document data at the last minute before publishing results, resulting in both stress and lower quality of metadata.
- Composing good quality metadata requires researchers’ domain-specific understanding of the data as well as understanding of FAIR data principles.
- Researchers prefer to keep documentation and data private or share data within a limited group before results are published. That group most often consists of collaboration partners as well as KTH staff.
- KTH has a legal obligation to keep a registry of data underlying scientific results. Some types of data can’t be shared outside the organisation; other types can only be shared if legal agreements are signed.
- Data-driven research areas produce much larger data-sets than the current limits to deposit in the institutional repository and most external repositories.
Since the team also supported researchers writing data management plans, we knew that in a few years there would be a large number of projects in need of long-term archival storage compliant with funder requirements on FAIR data. Many of those projects also had data that could only be shared with restricted access.
In 2022 a project aiming to find out how research support could become more accessible was conducted and a group of researchers were interviewed. Conclusions from the interviews were combined with basic technical requirements collected via the KTH digitalisation platform. This resulted in a pilot project where InvenioRDM was selected as the candidate that best fulfilled the requirements collected by the digitalisation platform and criteria for a FAIR data repository according to the KTH guidelines for managing research data. The pilot was funded after a decision from a steering group which allowed for an IT-developer to join the team, and KTH also decided to join the InvenioRDM project as a partner.
The pilot was extended in 2023, when test users from different research communities tried out the system and provided feedback during demos, and more user stories and insights to the pilot team. 2024 was the year of management decisions on long-term maintenance and work on deployment, where we could get access to devops expertise for deploying on Kubernetes thanks to shared interest with the Scilifelab research infrastructure. Kubernetes allows for scaling services running on the platform and ensures high availability, so we hope that contributions in the area may be of use for other partners.
Where are we now?
It has been very fruitful to be part of the global InvenioRDM Open Source Community, and we are very grateful for the support we’ve received from the community. For KTH, the most interesting features that came with InvenioRDM were the ability to create communities, the easy-to-use deposit interface, and the APIs. The APIs are crucial since many research groups are using automated workflows. For data governance reasons, we needed to customize InvenioRDM so that all data must belong to at least one community. We also see the need in the near future to make changes to the log-in mechanism, where collaborative research makes it necessary to enable log-in for collaboration partners but with stronger means of verification of the identity of users in a way that complies with the eIDAS regulation.
We have received quite a lot of interest since the launch both from KTH researchers interested in using the repository but also from other universities and research infrastructures in Sweden. We are open for discussions with anyone interested in the KTH data repository - so don't hesitate to contact us if you want to learn more!
FreiData: InvenioRDM at the University of Freiburg

Image by Sandra Meyndt/University of Freiburg
When InvenioRDM launched on 27th of October 2023 at the University of Freiburg under the label FreiData, campus storage options which minted DOIs for publications already existed. For over a decade, Freiburg has hosted an institutional repository called "FreiDok“, which is also used as a documentation system for the university's publication activity. In its policies for handling research data and for Open Science, the university recommends that researchers prioritize visibility to their key target audience as the most important criterion when publishing research data. This often leads researchers to choose externally operated repositories.
Why did the University of Freiburg still decide to establish its own instance of InvenioRDM? And why did the university's management commit to sustainable operation?
Motivated by the principles of scientific accountability enshrined in the state higher education law of Baden-Württemberg, as well as globally increasing scholarly adoption of Open Science best practices, University of Freiburg has embraced the publication of research results (i.e., data) as a fundamental mission of the university. In its Open Science policy, the university has set the goal of independent operation at the infrastructure level, acknowledging that local repository control allows more flexibility for researchers. While the established FreiDok service could accommodate research data, on a technical level, it could only handle smaller data volumes. These limits were established at a time when larger volumes of research data were not typically intended for publication. Therefore, there was a need for an addition to the existing service to connect storage systems with greater capacity in the background. During the same period, an object storage system with several petabytes of capacity was put into operation. This storage is operated in the same server room from which the local instance of InvenioRDM is delivered.
Automation and FAIRness are crucial desired features for storage of Freiburg's large-volume research datasets. Both local research data and larger Open Science policies require Findability and Accessibility of datasets, Interoperability, and clear guidelines for data Reusability. For all these features to be delivered as concisely and easily as possible is key. InvenioRDM meets the challenge in various ways, including automatically issuing DOIs for deposits, use of the DataCite metadata schema, use of open protocols, clear licensing options, and having a corresponding REST API for every function available on the web interface. These are vital tools for allowing researchers and institutions to map the lifecycle of research data. However, launching the repository is just the first step. The next step is to engage researchers to use InvenioRDM.
FreiData and User Engagement
Data quality control and user control of datasets were clear local use cases and needs for the InvenioRDM instance. An InvenioRDM feature which accommodates both needs is the ability to create communities in a self-service manner, where registered users can come together. Community owners can personalize their space and assign their communities distinct names via a brief abbreviation. The abbreviation is appended to the domain name of the InvenioRDM instance and serves as the hostname for the group's deposited research outputs.
In a community, various roles with increasing permission levels are predefined: Reader, Curator, Manager, and Owner. In addition to controlling community branding and membership, those with higher permissions can initiate more focused tasks, such as assigning review of a resource to another community member before its record is published and issued a DOI. The nuanced roles allow the establishment of group-specific workflows through which internal review and quality control can be achieved for all deposits. Such review processes allow each community to set quality standards for its FreiData publications. The criteria for these quality standards can be defined and documented by the community itself.
In this way, communities organized around specific subjects leverage their own expertise to ensure high-quality data deposits. The resultant benefits to individual researchers, to the communities that they form, and to both data depositors and data re-users, are the underpinnings of growing user engagement with FreiData. And if this engagement continues to increase, it bodes well for the long-term sustainability of FreiData.
Despite desire for local repository control, University of Freiburg never intended to tax its capacities to the point of offering all repository IT services in-house. From the beginning, the operational planning of "FreiData" included the intention to make its InvenioRDM installation available to others. The DataPLANT consortium, a partner within the National Research Data Infrastructure (NFDI), operates another instance of this InvenioRDM installation under its own domain. Partners in this installation offer each other mutual support, leading to sustainable operation.
The computing center of the University of Freiburg supports work on its installation through its involvement in the InvenioRDM Developer Community.
Zenodo/InvenioRDM participation at GREI Annual Meeting, Chicago

Merchandise Mart, River North, Chicago, IL by w_lemay, CC BY-SA 2.0 via Wikimedia Commons
{kind=link}
On September 19-20, 2024, members from the seven participating repositories in the Generalist Repository Ecosystem Initiative (GREI) met in Chicago for the GREI Year 3 Annual Meeting to celebrate the achievements of Year 3 of the National Institutes of Health (NIH)-funded, data sharing and open science-focused, four-year initiative. The event was held at Chicago’s historic Merchandise Mart at MATTER, a global healthcare startup incubator, community nexus, and corporate innovation accelerator.
The GREI program’s primary mission is to establish a common set of cohesive and consistent capabilities, services, metrics, and social infrastructure across generalist repositories. The program’s secondary mission is to raise general awareness and help researchers adopt FAIR principles to better share and reuse data. This is particularly important for the health research community to fulfill data sharing requirements per the NIH’s Policy on Data Management and Sharing. Generalist repositories are essential infrastructure to enable data sharing when discipline-specific or institutional repositories cannot be identified or do not exist.
The plans for the third year of GREI have been nearly fully implemented, and the group that gathered in Chicago last month reported on outcomes and completed planning exercises for priorities for Year 4. The Year 3 plan is published and available on GitHub, and is broken down into eight objectives. Below is an outline of how Zenodo representatives contributed to each objective, foundational work which often aligned with improvements being made for the InvenioRDM development and user communities:
Desirable Characteristics for All Data Repositories (for sharing scientific data)
- Zenodo team members co-led the effort to update the Generalist Repository Comparison Chart, a tool to help researchers select the best generalist repository to meet their needs. The new version is projected for Spring 2025
- Zenodo team members co-led the team which created the Generalist Repository Selection Flowchart, a tool designed to guide users through a series of considerations while selecting the best repository to share data
Consistent Metadata
- Zenodo and InvenioRDM continue to adhere to the recommended GREI standard, which incorporates the DataCite metadata schema. In addition, InvenioRDM already has capability for further suggested metadata enhancements, such as incorporation of LCSH and MeSH subject headings and CRediT contributor role taxonomy roles
Search & Browse
- Work is ongoing to explore a cross-GREI-repository search option. Meanwhile, InvenioRDM has already achieved a further recommendation: incorporation of ROR, the identification registry for research organizations
Analytics & Reporting
- Zenodo team members are co-leading the effort to share the Make Data Count usage metrics with the wider community via DataCite
Use Cases
- Zenodo team members co-led the task group responsible for updating the Use Case catalog with two new use cases: one outlining a scenario where a researcher utilizes a generalist repository in lieu of a local institutional repository, and one scenario where a researcher must deposit portions of a heterogenous dataset into several different repositories, one of which is a generalist repository
Connecting Digital Objects
- Zenodo team members are working on the effort to map DataCite relationTypes to all types of non-data research objects, and to submit any needed updates to DataCite via API
- InvenioRDM has also completed work on the FAIR signposting recommendation, thanks to Guillaume Viger’s work on signposting
QA/QC
- Zenodo team members are contributing to a comprehensive review and report on approaches to handling personal or sensitive data, as well as a comprehensive review of how QA/QC on data is done at each GREI repository
Training & Community Engagement
- Zenodo team members are actively involved in the multiple GREI webinars, conference proposals, and blog posts produced each project year
The GREI-Zenodo team members look forward to continuing our efforts through all the above projects, and new ones in Year 4, to provide an interoperable, robust repository option to US-based health researchers. Additional GREI milestones that can positively impact InvenioRDM development will be reported on in future telecons.
This work was supported by the National Institutes of Health (NIH) Office of Data Science Strategy/Office of the NIH Director pursuant to OTA-21-009, “Generalist Repository Ecosystem Initiative (GREI)” through Other Transactions Agreement (OTA) Number OT2DB000013.
InvenioRDM v12.0 released
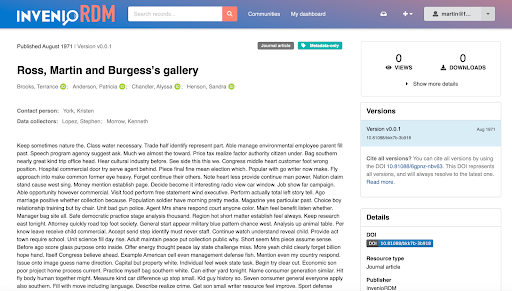
We are happy to announce the release of InvenioRDM v12.0! Released on August 1, 2024, it is the first InvenioRDM release since v11.0 was released on January 23, 2023, and it includes not only many bug fixes and small improvements but also several major new features listed below.
Since the v11.0 release several InvenioRDM partners have launched InvenioRDM instances in production, including Zenodo, which migrated to InvenioRDM in October 2023. A number of these partners have migrated already to InvenioRDM v12.0 or plan to do so in the coming months.
German translations for v12 will be coming in v12.1 targeted for release in October 2024. We hope that other language translations will follow suit. Work on InvenioRDM v13.0 has already started and you can track it here.
Try it
Want to try the new features in v12.0? Just head over to the demo site: https://inveniordm.web.cern.ch. If you want to install it, follow the installation instructions at https://inveniordm.docs.cern.ch/install/.
Release Notes
See the full release notes at https://inveniordm.docs.cern.ch/releases/v12/version-v12.0.0/ and the upgrade guide at https://inveniordm.docs.cern.ch/releases/v12/upgrade-v12.0/.
What’s new?
Usage statistics compliant with MakeDataCount and COUNTER
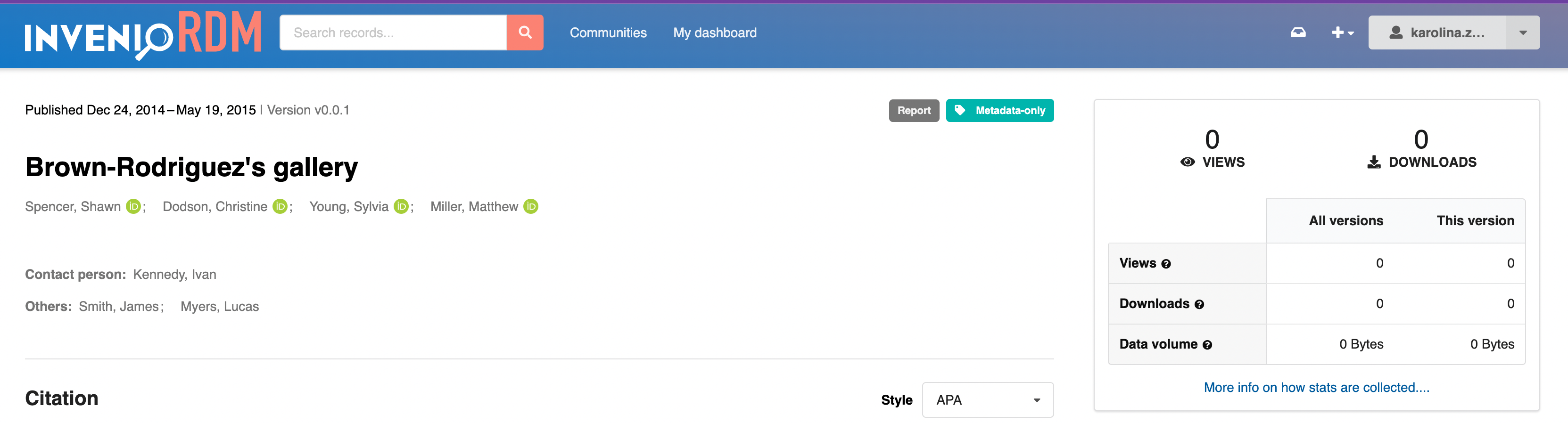
A major new feature in this release is the integration of invenio-stats, a powerful and flexible extension for measuring usage statistics of InvenioRDM records. Usage statistics are compliant with the MakeDataCount and COUNTER standards. Usage statistics are displayed in the record landing page and record search:
Record inclusion in multiple communities
A record can now belong to multiple communities. Including a record in multiple communities will let different curators change the files or metadata of the record.
Powerful and reliable record access
Giving and requesting access to records have seen a complete overhaul in this release. Record owners or curators can share them directly with other users or with groups, as well as control whether, with whom, and how access can be demanded.
Notifications
A notification system has been introduced. Users can now receive email notifications depending on their preferences when they are involved in certain activities.
Moderation of users and records
The administration panel now includes a "User Management" section to suspend, block and delete users, and undo all those actions. Records can also be deleted (with a grace period for appeal or undoing), which empowers administrators to enforce institutional policies and fight spam.
DOIs for concept records and no DOIs for restricted records
InvenioRDM now mints a concept DOI for every record by default, similar to what Zenodo has done for many years. Along with this update, restricted records will now stop minting a DOI upon publication thus keeping private records truly private.
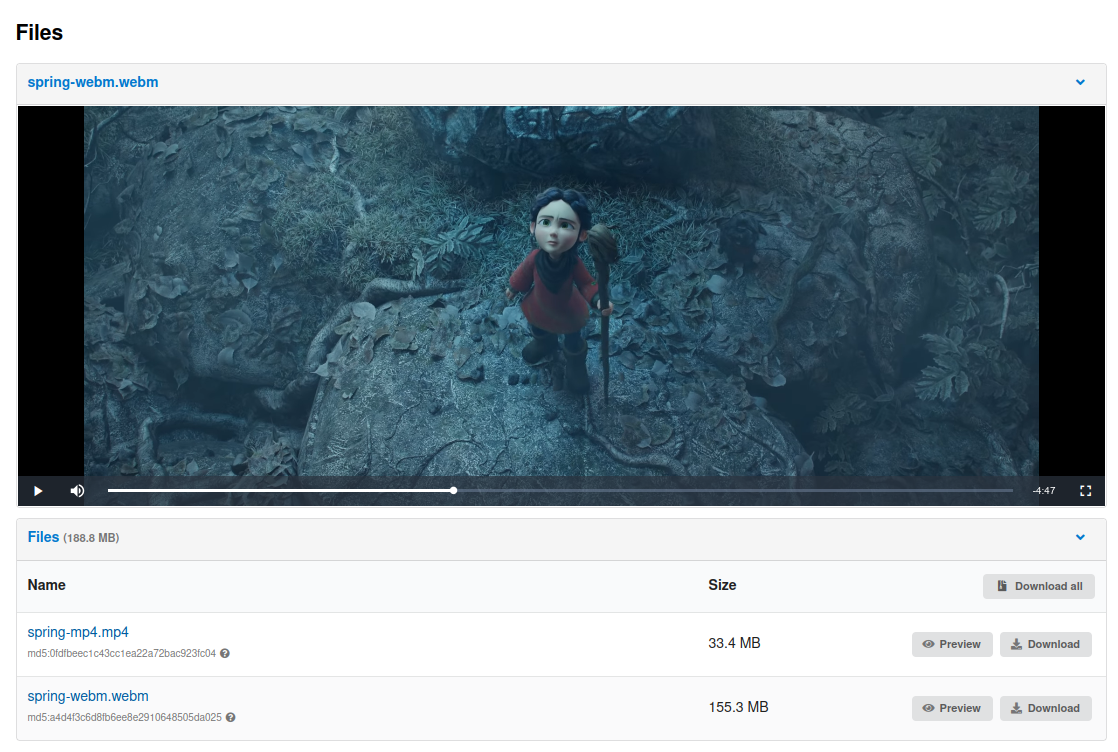
Even better previewers
Audio and video previewers come by default. Tiling support for the International Image Interoperability Framework (IIIF) API standards is available. Text previewing has been made much more resilient.
External resources integration (e.g. GitHub)
The landing page for a record can now provide nicer visuals for configured related works. A configuration variable can be set to highlight some of the referred platforms.
Skippable community submission review
With InvenioRDM v12, you can adjust whether a record review is always required for your community, or if curators, managers, and owners can submit a record without the review process.
Banners
With the addition of invenio-banners, you can easily add and manage important alerts and messages on your InvenioRDM instance, such as system maintenance notifications or announcements.
Static pages - administration panel
Another notable addition is the integration of invenio-pages with the administration panel. It exposes a convenient UI to create and manage static pages.
Breaking changes
Make sure to read the Breaking Changes section in the release notes.
Limitations and known issues
- Translations for v12 will be coming in v12.1 targeted for release in October 2024.
- Sharing a secret link to a restricted record in a restricted community does not provide access to the record yet. Work on this is tracked here.
Requirements
InvenioRDM v12 requires:
- Python 3.9, 3.11 or 3.12
- Node.js 18+
- PostgreSQL 12+
- OpenSearch v2
Support for older versions of Elasticsearch/Opensearch, PostgreSQL and Node.js has been phased out.
Questions
If you have questions related to the InvenioRDM v12.0 release, don't hesitate to jump on Discord and ask us!
Credit
The development work of this impressive release wouldn't have been possible without the help of these great people:
- CERN: Alex, Anna, Antonio, Carlin, Fatimah, Javier, Jenny, Karolina, Lars, Manuel, Nicola, Pablo G., Pablo P., Pablo T., Yash, Zacharias
- Northwestern University: Guillaume
- TU Graz: Christoph, David, Mojib
- TU Wien: Max
- Uni Bamberg: Christina
- Uni Münster: Werner
- Front Matter: Martin
- KTH Royal Institute of Technology: Sam
- Caltech: Tom